China, 17th Oct 2025 — Recently, a research team jointly formed by Agibot, Chuangzhi Academy, The University of Hong Kong, and others, published a breakthrough study that systematically explores three key dimensions of data diversity in robot manipulation learning: task diversity, robot embodiment diversity, and expert diversity. This research challenges the traditional belief in robotics learning that “more diverse data is always better,” providing new theoretical guidance and practical pathways for building scalable robot operating systems.
Task Diversity: Specialist or Generalist? Data Provides the Answer
A core question has long perplexed researchers in robot learning: when training a robot model, whether to focus on data highly relevant to the target task for “specialist” training, or to collect data from various tasks for a “generalist” learning approach.
To answer this, a clever comparative experiment was designed, constructing two pre-training datasets based on the AgiBot World dataset with identical sizes but drastically different task distributions:
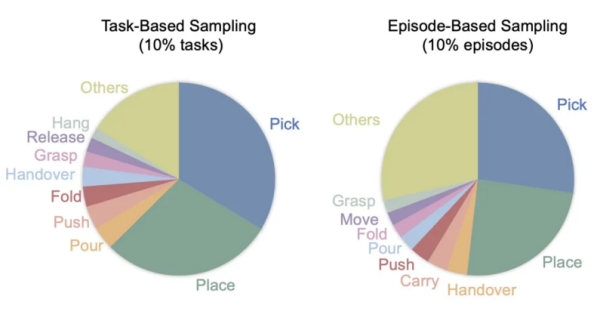
- “Specialist” Dataset (Task Sampling) – 10% of tasks most relevant to the target tasks were carefully selected, all containing the five core atomic skills required for evaluation: pick, place, grasp, pour, and fold. As shown in the figures, this strategy, while having lower skill diversity, is highly concentrated on the skills needed for the downstream tasks.
- “Generalist” Dataset (Trajectory Sampling) – 10% of trajectories from each task were randomly sampled, preserving the full task diversity spectrum of the original dataset. Although this approach resulted in fewer trajectories directly related to the target skills (59.2% vs. 71.1%), it achieved a more balanced skill distribution.
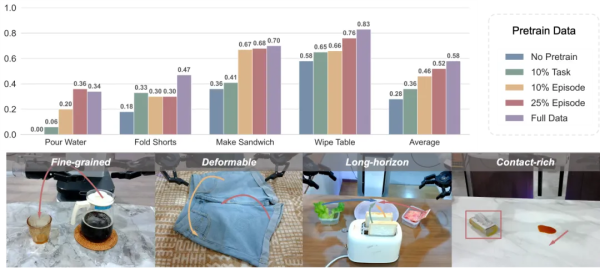
The results revealed an unexpected trend. As shown, the “Generalist” trajectory sampling strategy significantly outperformed the “Specialist” approach on four challenging tasks, with an average performance improvement of 27%. More notably, the advantage of diversity was even more pronounced on complex tasks requiring higher semantic and spatial understanding – for example, a 0.26 point increase (39% relative improvement) on the Make Sandwich task, and a 0.14 point increase (70% relative improvement) on the Pour Water task.
Why did diversity win? The analysis revealed that the trajectory sampling strategy not only brought skill diversity but also implicitly included richer scene configurations, object variations, and environmental conditions. This “incidental” diversity significantly enhanced the model’s generalization ability, allowing the robot to better adapt to different objects, lighting conditions, and spatial layouts.
Based on the discovery that “diversity is more important,” the research team explored a deeper question: given sufficient task diversity, does increasing data volume continue to improve performance? Experimental results show that the average score of the GO-1 model exhibited a stable upward trajectory as pre-training data volume increased. Crucially, this improvement followed a strict Scaling Law! By fitting a power-law curve, Y = 1.24X^(-0.08), the team found a highly predictable power-law relationship between model performance and pre-training data volume, with a remarkable correlation coefficient of -0.99.
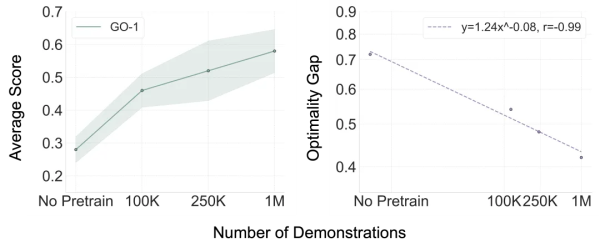
The significance of this finding lies not only in the numbers but also in a major breakthrough in research methodology. Past scaling law research in embodied intelligence primarily focused on single-task scenarios, small models, and no pre-training phase. This study extends scaling law exploration for the first time to the multi-task pre-training phase for foundation models, demonstrating that, given sufficient task diversity, large-scale pre-training data can provide continuous, predictable, and quantifiable performance gains for robot foundation models.
Embodiment Diversity: Cross-Robot Transfer Using Single-Platform Data
The robotics community has long held that for a model to generalize across different robot platforms, pre-training data must include data from as many diverse robot embodiments as possible. This belief led to large-scale multi-embodiment datasets like Open X-Embodiment (OXE), which includes 22 different robots.
However, cross-embodiment training introduces significant challenges: vast differences in physical structure, and inherent disparities in action and observation spaces between platforms complicate model learning. Facing these challenges, the team delved deeper: despite morphological differences, the action spaces of their end-effectors are essentially similar. When different robots make their end-effectors follow the same trajectory in world coordinates, they can produce comparable behaviors. This observation led to a key hypothesis: a model pre-trained on data from a single robot embodiment might easily transfer learned knowledge to new robot configurations, bypassing the complexities of cross-embodiment training. To validate this bold hypothesis, the team designed a “one versus many” experimental showdown:
- RDT-AWB: Pre-trained on the Agibot World dataset (1 million trajectories, single Agibot Genie G1 robot), containing no data from the target test robots.
- RDT-OXE: Pre-trained on the OXE dataset (2.4 million trajectories, 22 robot types), containing data from the target test robots, theoretically holding a “home advantage.”
Testing was conducted on three platforms: the Franka arm in the ManiSkill simulation, the Arx arm in the RoboTwin simulation, and the Piper arm in the real-world Agilex environment. In the cross-embodiment adaptation experiment in the ManiSkill environment, RDT-OXE initially showed its “home advantage,” slightly leading at 125 samples per task. However, a turning point occurred at 250 samples: RDT-AWB quickly caught up. As data increased further, RDT-AWB began to surpass RDT-OXE and widened the gap, a growth that followed a power-law relationship. This indicates that the single-embodiment pre-trained model not only achieves effective cross-embodiment transfer but also exhibits superior scaling properties.
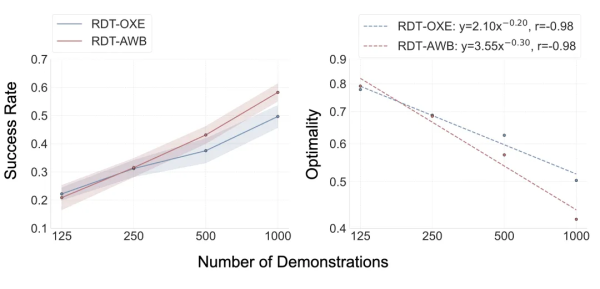
To ensure generalizability, in the real-world Agilex environment, RDT-AWB outperformed RDT-OXE on 3 out of 4 tasks, achieving comprehensive victory from simulation to reality.
Additionally, tests were conducted to evaluate the cross-embodiment capability of the GO-1 model (pre-trained only on Agibot World) on the Lingong and Franka platforms using a folding task. Even without seeing the task or the specific embodiment in pre-training, the model required only 200 data points to successfully transfer and adapt, with GO-1 + AWB achieving an average score 30% higher than GO-1 trained from scratch.

These results have disruptive theoretical and practical implications. Theoretically, they challenge the traditional notion that multi-embodiment training is necessary for cross-embodiment deployment, suggesting that high-quality single-embodiment pre-training offers a simpler path. Practically, this can drastically reduce data collection costs by focusing on high-quality data from a single platform and simplify training pipelines, offering a new path for cross-platform robot model application.
Expert Diversity: Identifying Harmful Noise to Enhance Learning Efficiency
An often-overlooked yet crucial factor in robot learning is Expert Diversity – the variation in demonstration data distribution arising from differences in operator habits, skill levels, and inherent randomness. Unlike standardized NLP or CV datasets collected from the internet, robot datasets consist of continuous robot motions highly sensitive to operator behavior.
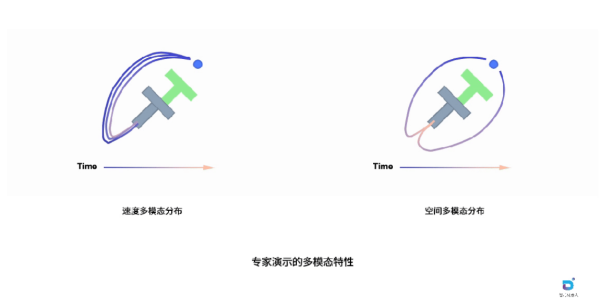
The classic PushT task, illustrated in the figures, exemplifies this phenomenon. Here, the robot (blue circle) must push a gray T-shaped object to a green target area. Despite the identical goal, the collected expert demonstrations show clear multi-modal characteristics. Spatial multi-modality is evident in different trajectory choices: the robot can approach from the left or right side of the object, forming distinct spatial paths, reflecting different operator understandings of the task strategy. Velocity multi-modality occurs when similar trajectories are executed at different speeds: even with similar paths, varying execution speeds produce entirely different demonstration profiles in the time dimension, with some operators acting quickly and decisively, others more slowly and cautiously.
These two types of multi-modality have completely different impacts on learning. Spatial variation represents meaningful task strategies; these diverse solutions should be preserved as they enrich the model’s understanding of the task and help prevent out-of-distribution (OOD) inference. However, velocity variation often introduces unnecessary noise, complicating current action-chunk-based imitation learning by forcing the model to learn these distribution characteristics simultaneously, increasing difficulty without adding substantive strategic value.
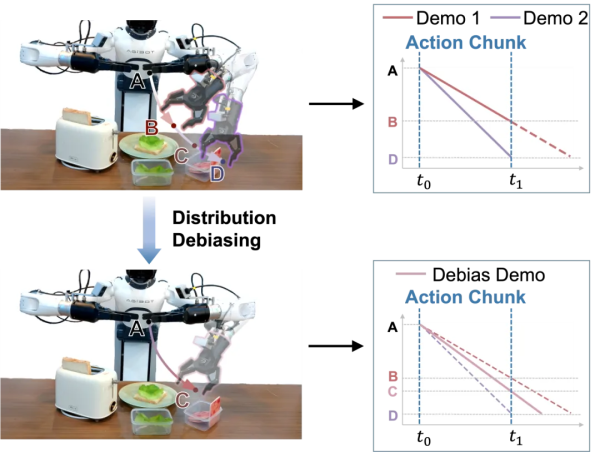
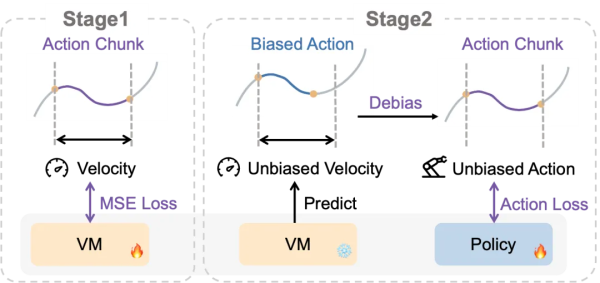
To address this challenge, the team proposed a clever two-stage distribution debiasing framework centered on introducing a Velocity Model (VM). In the first stage, the VM is trained to predict speed from action chunks using an MSE loss, learning the expected speed distribution for each input from the velocity-biased training data. This stage equips the VM with knowledge of reasonable speed distributions corresponding to different action patterns. In the second stage, during policy training, the VM first predicts an unbiased speed for each training sample. This predicted speed is then used to convert the original actions into unbiased actions. The policy is subsequently trained using these unbiased actions as supervision targets, effectively simplifying the distribution complexity and allowing the model to focus on learning the core task strategy without being distracted by speed variations.
The team validated the distribution debiasing approach on two representative tasks: Wipe Table and Make Sandwich. The model trained on debiased data, named GO-1-Pro, consistently outperformed the standard GO-1 model on both tasks and across all data scales. Notably, GO-1-Pro demonstrated exceptional data efficiency – achieving comparable or superior performance using only half the training data required by GO-1, effectively doubling data utilization efficiency.
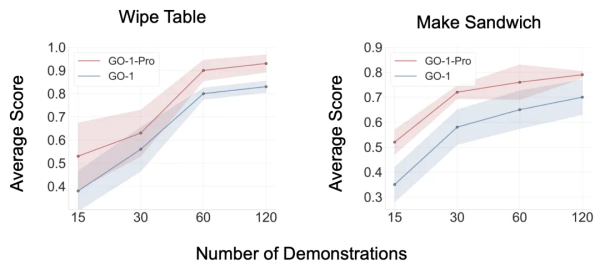
The advantages of the debiasing method were particularly pronounced in low-data scenarios. Under the scarce condition of only 15 demonstrations, GO-1-Pro improved performance on the Make Sandwich task by 48% and the Wipe Table task by 39%. In data-scarce settings, multi-modal distributions in speed and space create significant interference, hindering the model’s ability to capture core spatial patterns. By decoupling these confounding factors, the debiasing method enables the model to focus on learning essential spatial relationships, leading to more efficient and robust policy learning even with limited data, providing a practical technical path for enhancing model performance and data efficiency.
This study systematically explores data scaling for robot manipulation, revealing three key insights that challenge conventional wisdom: task diversity is more critical than the quantity of single-task demonstrations; embodiment diversity is not strictly necessary for cross-embodiment transfer; and expert diversity can be detrimental due to velocity multi-modality. These findings overturn the traditional “more diversity is always better” paradigm, proving that quality trumps quantity, and insightful curation trumps blind accumulation. True breakthrough lies not in collecting more data, but in understanding the essence of data, identifying valuable diversity, and eliminating harmful noise, charting a more efficient and precise development path for robot learning.
Media Contact
Organization: Shanghai Zhiyuan Innovation Technology Co., Ltd.
Contact Person: Jocelyn Lee
Website: https://www.zhiyuan-robot.com
Email: Send Email
City: Shanghai
Country:China
Release id:35602
The post Agibot Groundbreaking Release – New Perspectives on Task Embodiment and Expert Data Diversity appeared first on King Newswire. This content is provided by a third-party source.. King Newswire makes no warranties or representations in connection with it. King Newswire is a press release distribution agency and does not endorse or verify the claims made in this release. If you have any complaints or copyright concerns related to this article, please contact the company listed in the ‘Media Contact’ section
Disclaimer: The views, suggestions, and opinions expressed here are the sole responsibility of the experts. No Funds Special journalist was involved in the writing and production of this article.